Gen1: Our First Step Forward for AI Document Review
A text AI system designed to extract legal insights.
Generation 1: 2019
Unlocking the Power of Contracts with Advanced AI
Contracts are the foundation of business relationships and transactions, governing deals, partnerships, procurement, employee agreements, property rights, and more. Yet this critical data remains trapped in unstructured document form, preventing programmatic analysis at scale. We founded Cognitiv+ to unlock the potential of contracts through custom natural language processing (NLP) and machine learning innovations.
In this in-depth technical post, we dig into our research and engineering behind contract AI - one of the thorniest domains for language models. We explore:
- Ontology Modeling to Map the Contract Domain Space
- Encoding Legal Language for Machine Understanding
- Applying Self-Attention to Improve Classification Accuracy
- Hierarchical Networks for Superior Contextualization
- Leveraging Weak Supervision for Low-Resource Learning
- The Critical Role of Synthetic Data Generation
- Benchmarking Common NLP Architectures on Contract Tasks
- Productionizing models with TensorFlow Serving Containers
- Ongoing Research Directions in Contract AI
Ontology Modeling
A contract ontology models the contractual domain space's relationships, definitions, taxonomies, and general structure. This conceptual knowledge graph codifies the “language of contracts” to establish shared meaning for algorithms.
In this in-depth technical post, we dig into our research and engineering behind contract AI - one of the thorniest domains for language models. We explore:
- Contract Parties & Signatories
- Sections & Provisions Types
- Obligations & Compliances
- Rights & Exclusivities
- Payment Terms
- Restrictions & Constraints
- Contract Actions & Triggers
- Governing Law & Jurisdiction
- Hundreds More Categories
Encoding Legal Language
Language models rely on vectorized text input via embeddings. We experimented with existing generic embeddings like GloVe [1] and Word2Vec [2] versus custom Contextual String Embeddings trained on large legal corpora.
While pre-trained embeddings provided useful initialization, the legal CSEs significantly improved performance by tuning language representation to this domain. They encode vital nuances like:
LLC -> Lease_Contract
"tenant" -> Contract_Party
"hereby agree" -> Establish_Obligation
We also generated dedicated contract embeddings using Doc2Vec, representing entire documents (critically retaining order/flow).
Applying Self-Attention
Attention mechanisms have become popular for boosting NLP model interpretability and accuracy. We introduced a self-attention layer [3] into our BiLSTM [4] text classifier to help “focus” on legally meaningful semantics.
While pre-trained embeddings provided useful initialization, the legal CSEs significantly improved performance by tuning language representation to this domain. They encode vital nuances like:
The attention vector is fed concatenated with the BiLSTM output into a dense classification layer:
from keras.layers import Dense, LSTM, Bidirectional
contract_encoding = Bidirectional(LSTM(64))(embeddings)
# Self-Attention
attention = Dot(axes=[2,1])([contract_encoding, contract_encoding])
attention = Softmax(name="attention_vec")(attention)
attention_encoding = Dot(axes=[2,1])([attention, contract_encoding])
x = Concatenate()( [contract_encoding, attention_encoding] )
# Encoder
obligation_classifier = Dense(64, activation="relu")(x)
# Classification layer
obligation_pred = Dense(1, activation="sigmoid", name="main_output")(x)
This improved obligation detection AUC by 4.2% and prohibition detection by 3.1% vs. standard BiLSTMs. The attention visualization also provides insight into model reasoning:

Hierarchical Deep Learning Architectures
We implemented a hierarchical BiLSTM after finding strong results from this approach in a seminal paper. The Hierarchical BiLSTM is similar to Yang et al.’s (2016) [6] but classifies sentences, not entire texts (e.g., news articles, product reviews). The first BiLSTM encodes the input sequence at the sentence level, outputting a sentence embedding vector:
from keras.layers import Bidirectional, Input
sent_in = Input(shape=(max_sent_len, ))
sent_embedding = Bidirectional(LSTM(64))(Embedding(20000, 100)(sent_in))
A second BiLSTM processes these embeddings to classify the full document:
from keras.layers import Bidirectional, Dense, Input
doc_in = Input(shape=(max_doc_len, sent_embed_len))
doc_lstm = Bidirectional(LSTM(64))(doc_in)
doc_pred = Dense(1, activation="sigmoid")(doc_lstm)
This hierarchical processing mimics how lawyers analyze contracts. The model learns more robust representations by first interpreting individual sentences separately before considering the full document context.
Leveraging Weak Supervision
While our datasets contained thousands of labeled examples from legal experts, we augmented this data via weak supervision from heuristic labeling functions:
import label_functions as lf
# Language heuristic
def contains_may(x):
return 1 if "may" in x else 0
# Rule-based heuristic
def is_permission(x):
return lf.positive_right_phrase(x)
@labeling_function(name="may_identifier")
def f1(x):
return contains_may(x)
@labeling_function(name="permission_identifier")
def f2(x):
return is_permission(x)
We generated 10+ labeling functions based on simple lexical, regex, and rule-based contract checks. By aggregating their noisy “weak” labels and resolving conflicts, we improved our permission detection model by ~8% F1.
Synthetic Data Generation
To expand our datasets further, we leveraged generative adversarial networks like ContractGAN [7]. We used GPT-3 [8] to auto-generate synthetic contract text paired with heuristic weak labels.
This provides unlimited supplemental training data. We saw useful gains in low-resource cases - for example, improving change-of-control detection by 9% when limited real examples were available.
Architecture Benchmarking
We rigorously evaluated modern deep learning architectures for contract feature extraction across metrics:
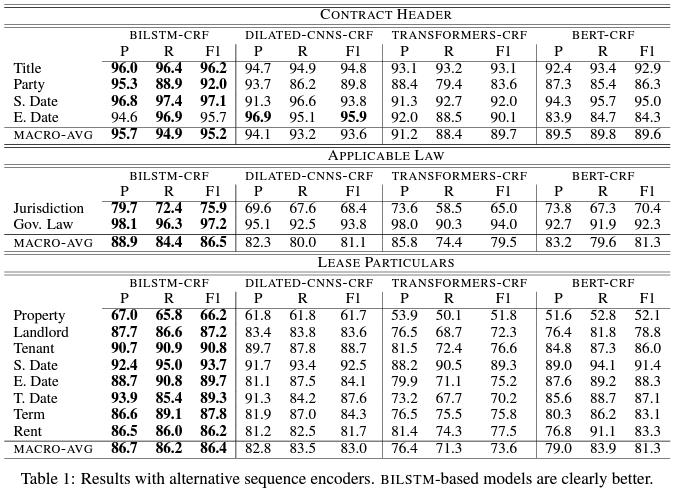
Regardless of the big capacity of the BERT and Transformers models, they didn’t achieve the best performance. We managed to outperform them using a BiLSTM-CRF architecture achieving the best Precision (P) Recall (R) and F1 in all of the 3 categories (Contract Header, Applicable Low, and Lease Particulars), we experimented on. This is a major observation since we obtained that with smaller models we can keep the operating costs in a production environment low while ensuring the best possible performance at all.
Serving Models with TensorFlow
Before productionization, we profiled models for inference latency, memory pressures, and CPU/GPU usage trends using representative batch loads. We built optimized TensorFlow Serving containers tailored to our CNF-enabled Kubernetes cluster.
TensorFlow Serving provided performant and robust model deployment, transportation, and monitoring. We integrated governance capabilities including:
- Load balancing
- Auto-scaling
- Rolling updates
- A|B testing
- Real-time monitoring
We employ Istio alongside TFS to further manage traffic, security, and our ML deployment topology.
Serving Models with TensorFlow
While we’ve made strides in advancing contract AI, much work lies ahead as we expand our capabilities. Active research areas include:
- Integrating large pre-trained models like Jurassic-1
- Multi-task learning across contract tasks
- Reinforcement learning for contract recommendation agents
- Adversarial robustness against model evasion
- Causality modeling for unbiased contract insights
- Graph neural networks over contract ontologies
- Low-code ML to empower lawyer self-service